在两年前,NVIDIA与Intel打了一场GPU与CPU谁更重要的口水战,表面上看,这场口水战只是双方交恶的意气之争,但实际上体现了计算业界的根本性分歧:CPU更适合通用性质的任务处理,而GPU更适合高并行的密集数学计算,这两者未来谁会更重要呢?
争论虽然没有得出答案,但Intel用行动来表达自己的野心:Larrabee处理器高调浮出水面,它针对高并行的流计算,当然也支持图形渲染,更关键的是Larrabee采用与X86类似的指令集来编程,摆脱了对固定式图形API的限制,从而能够实现更广泛的任务处理。Larrabee最后并没有获得成功,显然Intel在这个领域缺乏高超的设计水平,原型产品功耗巨大,性能又远逊于对手,强硬推出只是自取其辱。现在Intel暂时放弃了Larabee,放缓进入GPU领域的步伐,NVIDIA和AMD大大松了一口气,但Larrabee所要表达的意图却在图形业界开始被精确呈现。
Cypress与Fermi,向左走,向右走
一个像样的服装设计师,在设计自己作品的时候,总会先思考这些因素:未来将流行哪一种风格?客户又会喜欢哪一种款式?这个命题可以抽象出两种内涵:其一就是作品要针对哪一种应用,其二就是这种应用将采用何种形态来实现?事实上,新一代GPU的设计,也完全涵盖了这两个方面。
在图形领域,AMD的地位与NVIDIA“几乎”对等,“几乎”的意思就是还差那么一点点,至少我们可以看到,AMD在图形驱动的支持方面与对手差距甚远,NVIDIA可以为Windows、Linux和UNIX同时提供驱动,过气的老显卡也从未被抛弃;而AMD只能在Windows平台中保持对等,而且那些一两年前的GPU就得不到妥善的支持,当然更别提它的专业显卡驱动了。
另一方面,AMD无法像NVIDIA一样提供类似CUDA、PhysX这样的丰富软件平台,这让它在通用加速领域束手束脚,而这个领域的落后也很难朝夕赶上。再者,在单GPU芯片的设计方面,AMD一直缺乏NVIDIA这样的功底,迄今为止AMD都没有在晶体管数量方面超过NVIDIA—对结构相对固定的GPU来说,晶体管集成度在多数时候都代表性能的高低。
AMD很清楚自身的缺点,所以它采取灵活的策略来对付对手。显然,AMD的目标只是图形市场,希望能够在独立显卡领域胜过对手,同时图形芯片组再为自家的AMD64平台增加竞争力。这种立意决定了AMD在产品的设计上专注于图形性能本身,并且保持稳健的策略—在R600时代开始之前,AMD认为开发大型GPU芯片的难度越来越大,导致成本居高不下,同时市场铺设动作又非常迟缓。为此,AMD在自家CrossFire交火技术的基础上,制定了多芯片的开发策略。

以二敌一,开发中等性能GPU,再通过数量联合来实现高端性能,
这是一种代价最低,升级最容易的做法。
多芯片显卡的思想很简单,即GPU芯片不再追求全能和强劲,而只是实现全能性,保证对流行规格率先提供支持,其次便是芯片规模不要太大,以免给制造带来负担。同时,还要保证较好的功耗水准,在满足上述目标的前提下,实现最好的性能。显然,这种思路开发的GPU速度一定不是最快,但却可以在经济效益上做到最好,可以在短时间就上市。至于高端显卡,则可以通过双芯片,甚至四芯片并联的方法进行,以二敌一,来获得性能上的优势。
这种策略令AMD摆脱了新品推出不利的困境,并在商业上获得成功—尤其是在RV770 时代,NVIDIA的GT200完全失去了反击之力,现在AMD又在DirecX11显卡的争霸赛中,整整领先NVIDIA半年多。2009年9月,AMD发布代号为“Cypress(也就是RV870)”的Radeon HD 5870/5850系列显卡,率先进入DirectX11时代,低阶版的其他HD5000系列也很快上市,到现在为止,AMD的Radeon HD 5000系列已代替上一代产品成为主流。但NVIDIA仍只能拿GT200架构的GeForce GTX280/295应对,GT200其实只是2006年底发布的G80的延续,在规格方面比较落伍。很明显,NVIDIA目前的显卡产品不论在规格上还是硬件性能上都全面落败。相信这也是NVIDIA在GeForce FX5800以后遭遇的最大危机。

2009年9月发布的Radeon HD 5870,是第一款支持DirectX 11的GPU。
然而,NVIDIA高层和科学家们似乎不以为然,将全部注意力放在即将出炉的Fermi身上,他们始终保持高昂的热情,对这款革命性的GPU保持坚定信念。这种信念的内在动力,就在于Fermi与传统GPU已有了根本性的区别。在Fermi的开发工作启动之初,NVIDIA还在图形市场上占据显著优势,它所考虑的并不仅仅是保住自己的王座,而是希望能将GPU延伸到更广泛的领域,获得新的增长点。由于欠缺CPU业务,NVIDIA必须顾虑未来面临Intel和AMD的全平台竞争,很明显,假如NVIDIA只有传统的GPU,那么未来它必定是死路一条—Intel和AMD在某一天很可能甩开业界标准来打造属于自己的封闭平台,届时NVIDIA即便拥有世界上最好的图形技术,那也毫无用处。复杂的CUDA Core设计和缓存系统大大增加了Fermi的规模,
它的晶体管总量达到史无前例的30亿个,给制造工作带来巨大困难。
有鉴于此,NVIDIA要求它们的新一代产品要更加全能,能够胜任广阔的密集计算要求,而不仅仅只是用作图形渲染。NVIDIA希望它能够进入PC和游戏机之外的更多设备中,比如超级计算机、平板电视以及未来任何需要数字视觉的应用领域。
Fermi处理器,脱离GPU羁绊,专为通用而生
然而,现行的G80/GT200架构虽然具有非常不错的灵活性,但远不足以完成如此重大的使命。NVIDIA的高层作出激进的决策:那就是全部推倒重来—这就是Fermi的出台背景。Fermi被打造成一款高度灵活的处理器,除了图形渲染的基本职能,它还整合了PhysX物理处理器以及光线追踪处理器,同时让每个计算单元都拥有自己的缓存系统,可以高效地完成高负荷的浮点计算任务,比如对视频的实时优化编码,执行“任意妄为”地渲染指令、DNA排序、宇宙探索、质数计算等等,当然还包括物理计算和光线追踪计算—这些过去是CPU的专属应用。
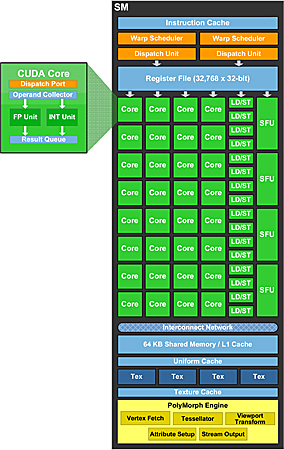
用户也许会发问:“从CPU手中抢到这些任务,对我们会有什么好处么?会不会像那些CPU整合GPU之类的噱头而已?”其实这种好处相当显著:CPU所执行的是X86指令,程序可以任意编写,完全没有使用限制,灵活是它的最大优点;另外,CPU是被设计来执行诸如任务处理之类的整数任务,固定式的浮点计算并非其特长,虽然CPU设计者始终不遗余力增强它的浮点性能。与此不同,Fermi采用一种高度并行的计算结构,它拥有多达512个CUDA计算单元,每个单元都有缓存,作为一个基本的计算单位,这些单元可以同时进行浮点计算的处理。并行度远非CPU可比—AMD的GPU虽然有更多的流处理单元,但这些单元并没有缓存系统,只是被动地接受上级数据计算后输出,通用性非常有限,加上AMD并没有提供理想的开发工具,令开发者无从下手。

Fermi的CUDA核心,拥有完整的浮点和整数计算单元,
不再在整数计算方面瘸腿,具有高度自主性。
其次,Fermi的每个CUDA核心,都在浮点计算单元之外加上整数处理单元,可执行完整的32位整数计算任务,而后者在过去只能通过模拟实现,且仅能计算24-bit整数乘法而已;同时Fermi引入了复合乘加运算机制(Fused Multiply-Add,简称FMA),每个周期可执行512单精度浮点或256个双精度浮点数运算,而上一代G200仅能支持单精度的FMA操作。当然,所有这些FMA运算都基于IEEE 754-2008浮点算法,计算结果不会出现差错。此外,Fermi的双精度浮点(FP64)性能也大大提升,峰值执行率可以达到单精度浮点(FP32)的1/2,而过去只有1/8;AMD Cypress/RV870核心的双精度浮点性能也只有单精度浮点的1/5—例如Radeon HD 5870的单精度性能达到2.72TFlops,但双精度处理时仅有544GFlops。
第三,Fermi引入了真正的缓存设计,每32个CUDA核心被配置成一组SM(Streaming Multiprocessor)流处理器,每组SM拥有64KB可配置内存,可以根据任务的性质部署成16KB共享内存加48KB一级缓存,或者48KB共享内存加16KB一级缓存的形式,从而满足不同类型程序的需要。此外,整个芯片还共享768KB的二级缓存,方便SM计算单元的输入输出—这些显然都是为通用计算而准备。
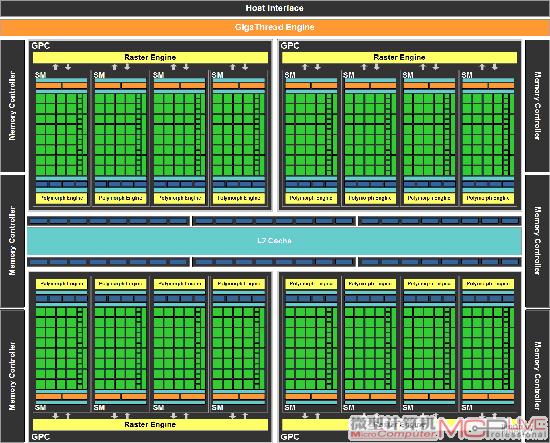
Fermi拥有16组SM流处理器,每组都具有自己的缓存
和内存系统,能够独立地完成各种密集计算应用。
计算核心的大幅增强以及缓存系统的纳入,让Fermi成为一枚高度通用的浮点处理器而非传统的GPU。其实,从数学角度来看,无论是图形渲染的浮点运算,还是物理处理、光线追踪、视频编码处理、DNA排序还是其它的数学计算,在本质上都是相同的单精度浮点或双精度浮点计算,最基础的数学计算机制也完全相同,区别仅在于采用不同的算法—如果算法可以用软件方式输入,GPU依照这种算法进行结构部署并处理,那么就可以实现了通用的浮点处理任务。我们可以打个简单的比喻:这个模式相当于将CPU内的浮点计算单元完全搬移出来,作适应性改造之后再放到GPU上面,同时大大增加它的数量—这就是NVIDIA Fermi的设计立意。
Fermi被打造成通用型浮点处理器,加上NVIDIA一向对性能要求极高,Fermi就不可避免地成为又一个巨无霸。在产品展示之时,外界咨询为何Fermi屡屡跳票,几乎创下NVIDIA新的历史。NVIDIA的高管不禁大吐苦水:要设计出这个超大超强的玩意实在是太难了!的确,Fermi需要为每个单元建构缓存系统,要确保如此众多的核心能够高效率地协作和共享,这种难度明显超出常规的多核处理器(目前的多核CPU最多只需要应对12核的协作)。NVIDIA高层与它们的科学家都深知Fermi的革命性,虽然产品屡屡因这样那样的问题跳票,但他们几乎不以为意,而对于未来始终充满自信。
Larrabee理想的实现,Fermi与CUDA、Tesla平台通吃密集计算市场
Fermi与AMD Cypress/RV870 GPU的不同设计立意,意味着GPU的道路开始分道扬镳—从商业上讲,Cypress/RV870体系下的Radeon HD5000家族都具有易于生产、价格便宜、功能齐全的特点,会在眼前的商业市场上获得追捧,但它们实质上仍只是一款图形处理器,与NVIDIA第一代GeForce 256并没有本质的不同。虽然Fermi面临生产上的种种难题,但只要Fermi迈过这道坎,它便与对手站在截然不同的制高点—回溯历史,我们不免有所感慨,AMD这些年间一直为整合ATI,并在图形市场超过NVIDIA而努力,而NVIDIA则将目光放在更广阔的空间,并为自己的下一个十年筹划布局。
Fermi代表通用浮点处理器的趋势,这其实是Intel Larrabee想要做的事情。我们知道,Intel在设计Larrabee时完全没有依照GPU的规范,而是另起炉灶,创造了一套基于X86的指令系统,借助这套指令,Intel可以为Larrabee编写各种不同的API接口,而API的升级也与硬件完全无关—比方说Intel能够仅通过升级驱动程序就实现从DirectX 10到DirectX 11的跨越,这是NVIDIA和AMD所代表的传统GPU势力所无法实现的。同样,Intel也可以推出各种不同功能的通用加速接口,而为Larrabee编程,就好象给目前的X86 CPU平台编写程序一样非常简单,Intel希望通过这种方式通吃密集计算市场,成为新领域的王者。

CUDA、Fermi Tesla共同构建NVIDIA的密集计算系统,在这个领域NVIDIA未逢对手。
非常讽刺的是,Fermi现在将承担起实现这个梦想的使命,它所依赖的便是NVIDIA的CUDA和Tesla平台—前者作为应用程序的开发接口,允许开发者采用C/C++语言来对GPU进行编程;后者则是针对性的硬件系统,我们可以将它们看作是特殊的显卡,计算核心仍然是GeForce GPU,只是面向的任务迥然不同。经过这么多年的推广,CUDA和Tesla平台已在许多专业领域获得应用,实际上它们也是GPU进入密集计算领域的唯一选择。
在这个全新的领域中,NVIDIA现在没有任何对手,Fermi的出台无疑将进一步巩固了NVIDIA的标准地位,我们已经可以嗅到Fermi大举进入超级计算市场的气息,这种感觉正如NVIDIA当初拿出GeForce 250 GPU之后,环顾四周S3、Matrox、3dfx纷纷倒下的情况。在未来的TOP500超级计算系统中,NVIDIA的市场占有率最终将超过Intel、AMD和IBM这些传统势力,原因非常简单:在获得同等计算性能的条件下,NVIDIA Tesla系统的花费只是传统CPU方案花费的几十分之一,何况基于Fermi的Tesla平台无论在性能还是灵活度上都有相当大的提升,这将对超级计算机的建设者带来致命吸引力。我们可以预见,今后的超级计算机和工作站专业领域,基于传统CPU+Fermi的混合架构会将成为最好的选择,NVIDIA也将在这个利润丰厚的新市场中找到自己的位置。
我们同样相信,作为先行者的Fermi不会永远高枕无忧,Intel并没有完全放弃它的Larrabee计划,作为理念的开创者,Intel仍然寻求进入该领域的可能,以保证CPU不会因为时代前进而被边缘化。作为竞争者的AMD,在未来产品中势必会增加这方面的机能—尽管AMD没有类似CUDA这样的开发平台,但借助开放的API标准,AMD将会逐步升级并进入到这个领域,虽然开发环境的支持不力将会长期困扰AMD。
CPU迎战Fermi,纳入新的协处理机制
如果事态就这么自然地发展,Fermi将不断蚕食原本属于CPU的领地—其实它本来就是CPU中的浮点运算单元,只不过变得异乎寻常的强大而已。加上NVIDIA摆脱了通用标准的制约,形成一个强大的封闭平台,这样将会与Intel的CPU中心平台和AMD的双线兼顾平台,形成角度不同的三国鼎立。
很显然,像Off ice办公软件、Web浏览器、IM即时通讯这样的商务软件不会消耗多少CPU资源,再低端的处理器都可以很好地运行这类整数运算任务。假如不是Flash帮忙,高性能CPU的用处实在是非常小了。不过,Adobe的Flash现在也在支持CUDA平台,利用GPU进行加速,微软的IE9也加入了GPU加速,倘若诸如交互动画和网络视频这些消耗CPU大的应用都依赖GPU运行,那我们还需要高性能CPU来做什么呢?
Intel如日中天的背后,潜藏着这样的危机,应用形态的改变完全可能颠覆整个产业,在短短的时间内将彻底改变产业形态。作为半导体业首屈一指的巨头,Intel显然不会坐以待毙,实际上,早在数年前提出的Many-Core“众核”计划便是针对此种未来而准备。
Many-Core采用主处理器+协处理器的设计思想,主处理器便是我们常说的CPU,协处理器则是拥有特殊功能的计算逻辑,比如高清视频加速、Java解释执行、Flash硬件加速等。每一个协处理器都执行特定的应用,而那些应用如果由CPU来完成的话就会非常低效。在Intel的最初蓝图中,Many-Core将在2010年后开始被导入,不过迄今为止Intel还没有这方面的行动,这未免让它显得落伍。如果与Fermi对比,我们发现Intel的Many-Core虽然结构完全不同,但是思想殊途同归:都是由专用部件来完成CPU所不擅长的任务,所不同的是Many-Core只是Intel过去的远景构想,不幸的是实现这个构想的却是NVIDIA的Fermi。
Fermi以另一种方式实现了Intel的梦想,并开创了一个全新的应用领域
在新发布的Core i3处理器中,我们看到图形核心被集成于处理器芯片内,不过这种整合只不过是“积木游戏”,对性能与应用没有任何的影响力。虽然Larrabee计划的失败看起来轻描淡写,但实际上完全可能会令Intel陷入一场突如其来的重大危机。
与Intel相比,AMD在CPU方面反而没有这种压力,这完全得益于来自ATI图形部门的贡献。AMD不会有改变CPU构造的动机,它的目标比较务实,只要能够从Intel手中不断抢夺市场份额,企业能够正面增长就没问题,哪怕自身缺乏改变未来的宏图大志。毕竟对于一家被糟糕的财务压垮多年的半导体企业,我们委实不应苛求太多。
现在,Adobe Flash和其它交互网页是CPU的最后堡垒,我们有理由相信,在未来的三年内,所有Flash元素都会实现GPU加速,同时,3D游戏对CPU的依赖将继续减弱,如果没有高负载的任务来接手,高性能CPU的市场将会缩小,这对于传统CPU厂商来说是可怕的前景。
通用GPU之于消费用户的意义
高度通用性的GPU,将会令传统的PC能够做许多过去难以想象的事情,而这种变化并不仅是在专业领域,实际上在娱乐应用中,新一代GPU将必不可少。
在2008年2月,东芝曾推出一款搭载Cell芯片的笔记本电脑,该芯片拥有多个协处理器,具有很强的浮点性能,在这部笔记本电脑中,Cell的任务是优化正在播放的视频:在传统模式下,视频清晰度低,画面色彩较为黯淡,而经过Cell的处理,画面变得清晰锐利,色彩鲜活,观赏性大大提升了。其次,对一些手持拍摄的视频,由于摄像机不稳造成画面严重抖动,经过Cell处理后所得到的视频可以变得非常稳定—假如拿普通的CPU来干这件事,这类转化过程需要数十小时之久,而Cell芯片仅需要2~3小时的时间。
未来的通用GPU同样将具有这样的功能,这种视频优化和转化处理,都需要极高的浮点运算能力,即便是目前最强的12核处理器都难以胜任;而只要有软件支持,类似Fermi这样的通用GPU就可以轻松实现这一点。鉴于这种功能实用意义巨大,我们认为视频播放器的开发者在今后会积极导入这项技术。
3D电视是目前电视机业界的热点,鉴于3D视觉模式的巨大吸引力,我们认为3D电视机在未来5年内将淘汰传统的2D电视成为主流形态。不过,电视台和电视剧的拍摄可来不及作出这么激进的转变,至少要到5年之后,3D频道才会陆续开播,而2D信号在漫长的时间内都还是主流。为了将2D信号转变为3D信号,电视机厂商就必须额外设计视频转换芯片,而高清视频流所需的超大计算量远非一般的处理器所能实现—显然,这个新兴市场也有望成为Fermi的新增长点,而且Fermi的可编程性质让它可以为所有的电视机厂商提供不同的解决方案,只要NVIDIA在未来能够拿出低功耗和成本更低的产品,并且推广得当,完全可以在这个新兴市场中获益。
如果回到3D游戏的老本行,Fermi所代表的高度通用平台也更具吸引力—强劲的物理性能与光线追踪性能是Fermi的杀手锏,前者基于PhysX团队的成果,是一种真正硬件级的物理计算方案,游戏开发者完全可以按照自己的意图来构建场面宏大的游戏场面,比如剧烈爆炸、雨雪和雪崩这些涉及到大量运动物体的自然场景都可以在虚拟世界中出现。而光线追踪的首度引入,则意味着3D游戏能够实现超一流的现实光影效果。与此相比,AMD所忠实代表的DirectX 11平台会显得黯淡无光,只要游戏开发者不想落伍,自然会在游戏中额外再加入PhysX物理支持和Fermi的光线追踪技术,鉴于这两项都是专有技术,竞争对手根本无法获得,只要拥有足够多游戏的支持,PC用户们会很自然地向NVIDIA倾斜,这也是NVIDIA在设计Fermi时的另一个初衷。
革命性的融合,通用GPU终将增加CPU功能
CPU工业也许还有三年时间来作出应对,而在这三年间,我们相信Fermi架构也不会踯躅不前。显然,Fermi上市时会遭遇发热巨大、价格高昂或者良品率低的问题,不过这些问题照例会在半年左右的时间里获得解决;接下来,NVIDIA会对Fermi结构作出优化并衍生出中低端和移动型号,这样在一年左右时间里,NVIDIA才能将Fermi推向主流市场的地位。
从表面上看,这种动作非常的迟缓,远远落后于AMD。不过NVIDIA将更关注软件平台的延伸—GPU在完成物理计算和光线追踪的加速后,现在要进入Flash加速、网页渲染加速和实时视频优化两个领域,Adobe在Phot oshop、Acrobat中明确采用CUDA进行加速,Flash的加速同样基于此,如果它能够在两年左右时间内拿出完美的解决方案,再经过1~2年的时间网页设计师都作出改变,那么一个新时代就产生了:Fermi这种通用GPU将取代传统CPU,承担PC系统的关键计算工作,此时CPU的性能高低对系统影响有限,消费者大概不会再关心它是Intel还是AMD。
再接下来,通用GPU中整合一些X86 CPU的功能是再自然不过的事情了,实际上所整合CPU根本不必有多么高超的性能或者多少个核心。这时你将看到,以GPU为核心的混合计算芯片将就此产生,同Intel、AMD的CPU为核心混合处理器具有相同的表面形态,但这两者的本质却截然不同。
我们认为这种融合方式更贴合未来的发展实际:今天的Office 2010相对于十年前的Office 97,在基本的商务功能方面并没有大的改变,对用户来讲,这两者最大的不同只是视觉界面。
再往后的五年,估计这类软件不会有本质性的进步,网络协同及云计算才是未来的方向所在,但这种网络中心的应用模式对CPU的要求反而更低。相反,视觉领域的应用方兴未艾,人们对于视觉的要求越来越苛刻:从VCD、DVD到标清、高清视频,再到3D化,未来甚至包括网页都会朝着这方面发展,这些新兴的应用势必对GPU依赖越来越高,加上未来3D游戏对高真实度交互体验的孜孜以求,我们相信GPU的重要性将越来越高,直到某一天突破临界点成为计算系统的核心。
圈地运动,争夺编程者的支持
对于这样的前景,CPU厂商们都要有足够的心理准备,对Intel而言,最好的举措就是重启Larrabee计划,假如无法在性能上赶上对手,那么作为新一代的整合GPU也是非常合适,关键在于Intel必须及早拿出相应的开发包和指令系统。第二个选择就是增强自身GPU的通用性,使之在商务领域能够保有自己的特点,而不会在面对未来应用时手足无措。
这种走向能够实现,决定权其实并不在NVIDIA、AMD或Intel等硬件厂商手中,真正的关键在于,软件开发者是否买账?这取决于Fermi平台能有多大的吸引力和多高的成熟度,但无论如何,我们都相信接下来的五年,CPU-GPU的平衡将会被打破,惯性提升性能的发展模式也走到了尽头,产业界的洗牌在所难免。那么,再下一次的洗牌,会是人工智能的实现吗?
新一轮战役,新一轮图形市场的竞逐
Fermi拥有更先进的理念,但先进的理念并不意味着马上就能够在市场中占据优势,NVIDIA花费巨大的精力来打造Fermi,很大程度上是为企业的长远未来考虑,但这种激进的设计在短时间内很难体现出优势,反而可能在现实中遭遇挫折。
Fermi最主要的市场依然是PC领域,游戏玩家们最关注的是3D性能、价格以及功耗方面的优势,而产量对于市场铺设同样极为重要。首先,我们来看看它的3D性能,评测结果清晰地显示Fermi架构的巨大威力:GTX480(Fermi架构的最高阶型号)在3D游戏中完胜对手Radeon HD 5870,平均领先幅度达到25%,虽然某些游戏领先幅度较轻微,但在多数游戏中GTX480的性能优势都非常显著,如果游戏本身支持PhysX,GTX480的性能优势更可平均高出200%。显然这些优势来自于Fermi近乎华丽的设计。
不过,Radeon HD 5870虽然落败于GTX480,但它的价格要便宜得多:GTX480零售价为499美元,Radeon HD 5870只有379美元,后者更经济;其次,Radeon HD 5870的功耗水准为27W(空闲)/188W(满载),而GTX480的满载功耗高达295W,只有配备600W的高功率电源方可满足需要,这明显增加了系统的构建成本—无论从费效比角度还是能效比角度,Radeon HD 5870都具有明显的优势。
GTX480虽然是当前的单GPU性能之王,但却不是显卡之王,AMD双芯的Radeon HD 5970依然可以在多数项目中轻松地击败它。Radeon HD 5970早于2009年11月份发布,时间上已整领先4个月,它的功耗水准也同GTX480相当—而受到功耗的限制,利用双GTX480芯片来搭建单显卡的计划几乎不可能实现。
在主流市场,NVIDIA计划推出Fermi架构的GF104 GeForce GTS 400系列,不过发布时间最快是在今年夏天,甚至可能到第三季度。换言之,如果主流用户想在上半年购置DirectX 11显卡,那么Radeon HD 5000系列依然是唯一的选择,AMD有充足的时间来占领独立显卡市场。或许正是因为这些原因,AMD高层对于Fermi的到来充满底气,AMD官方发言人Dave Erskine在接受访谈时对媒体表示:“Radeon HD 5970在发布4个月后依然是性能领先者;HD 5870在发布半年后依然是不争的赢家;同时AMD拥有从旗舰到入门的全系列DirectX 11显卡产品线,包括ATI Eyefinity技术在内的诸多先进特性,Radeon 显卡依然是消费者心目中的最佳选择。”
毫无疑问,NVIDIA应该在接下来的半年间解决生产问题,这个巨无霸的芯片令制造方吃尽苦头,低良品率和高成本是最大的致命伤。NVIDIA很难在2010上半年有多少作为,只有主流产品线全员到齐之后,NVIDIA才有机会夺回市场,问题在于,AMD也不会停步不前。

